MySQL日常命令笔记:查看日志和配置文件位置
mysql的sql语句
查看日志和配置文件位置
配置文件
root@8cebc228cfea:/# mysql –verbose –help|grep -A 1 ‘Default options’
Default options are read from the following files in the given order:
/etc/my.cnf /etc/mysql/my.cnf ~/.my.cnf
日志
https://dev.mysql.com/doc/refman/8.0/en/slow-query-log.html
MySQL常见的日志类型包括:
错误日志(error log,https://dev.mysql.com/doc/refman/8.0/en/error-log.html)
- show variables like ‘%log_error%’;
二进制日志(binary log)
慢查询日志(slow query log,https://dev.mysql.com/doc/refman/8.0/en/slow-query-log.html)
show variables like ‘%slow_query_log%’;
慢查询日志默认是关闭的,通过如下命令将其开启:
1
SET GLOBAL slow_query_log=ON
一个查询消耗多长时间被定义为慢查询呢?MySQL是通过long_query_time这个参数来控制的:
1
SHOW VARIABLES LIKE '%long_query_time%'
除此之外,如果查询没有使用索引,那么被记录到慢查询的日志概率性较大,MySQL 提供了
log_queries_not_using_indexes参数来控制是否将没有使用索引的查询记录到慢查询日志里面:1
SHOW VARIABLES LIKE '%log_queries_not_using_indexes%'
Variable_name Value log_queries_not_using_indexes OFF log_queries_not_using_indexes参数默认是关闭的,我们可以将其打开,1
SET GLOBAL log_queries_not_using_indexes=ON
如果
log_queries_not_using_indexes打开了,MySQL提供了log_throttle_queries_not_using_indexes参数来控制每分钟最好写入多少条这样的记录到慢查询日志:1
SHOW VARIABLES LIKE '%log_throttle_queries_not_using_indexes%'
Variable_name Value log_throttle_queries_not_using_indexes 0 默认是0,代表没有限制。
explain
查看存储引擎
1 | -- 查看支持的存储引擎 |
设置存储引擎
1 | -- 建表时指定存储引擎。默认的就是INNODB,不需要设置 |
查看当前数据库的事务隔离级别
1 | show variables like 'tx_isolation'; |
数据库的基础命令
连接
mysql -h主机地址 -u用户名 -p用户密码 (注:u与root可以不用加空格,其它也一样)
断开
- exit (回车)
查看当前数据库
- select database();
显示数据库
- show databases;
- show dbs;
显示数据表
- show tables;
显示表结构
describe 表名;
desc 表名;
Field 字段名 就是你字段的名字
Type 字段类型 说明了你定义的字符类型 注意:unsigned[无符号] 说明这个字段不能为负
Null 是否为空 定义了字段名是否可以为空
Key 索引 在mysql中key 和index 是一样的意思,这个Key列可能会看到有如下的值:PRI(主键)、MUL(普通的b-tree索引)、UNI(唯一索引)
Default 默认值 定义了该字段的默认值
Extra 其他信息
使用库(选中库)
- use 库名;
表的操作
查看表的信息
查看索引
SHOW INDEX FROM <表名> [ FROM <数据库名>]
Table 表示创建索引的数据表名,这里是 tb_stu_info2 数据表。
Non_unique 表示该索引是否是唯一索引。若不是唯一索引,则该列的值为 1;若是唯一索引,则该列的值为 0。
Key_name 表示索引的名称。
Seq_in_index 表示该列在索引中的位置,如果索引是单列的,则该列的值为 1;如果索引是组合索引,则该列的值为每列在索引定义中的顺序。
Column_name 表示定义索引的列字段。
Collation 表示列以何种顺序存储在索引中。在 MySQL 中,升序显示值“A”(升序),若显示为 NULL,则表示无分类。
Cardinality 索引中唯一值数目的估计值。基数根据被存储为整数的统计数据计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL 使用该索引的机会就越大。
Sub_part 表示列中被编入索引的字符的数量。若列只是部分被编入索引,则该列的值为被编入索引的字符的数目;若整列被编入索引,则该列的值为 NULL。
Packed 指示关键字如何被压缩。若没有被压缩,值为 NULL。
Null 用于显示索引列中是否包含 NULL。若列含有 NULL,该列的值为 YES。若没有,则该列的值为 NO。
Index_type 显示索引使用的类型和方法(BTREE、FULLTEXT、HASH、RTREE)。
Comment 显示评注。
创建表
创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
1 | 方法1: |
插入指令
| 指令 | 已存在 | 不存在 | 举例 |
|---|---|---|---|
| insert | 报错 | 插入 | insert into names(name, age) values(“小明”, 23); |
| insert ignore | 忽略 | 插入 | insert ignore into names(name, age) values(“小明”, 24); |
| replace | 替换 | 插入 | replace into names(name, age) values(“小明”, 25); |
SQL语句中删除表数据drop、truncate和delete的用法
- drop table 表名称 eg: drop table dbo.Sys_Test
- truncate table 表名称 eg: truncate table dbo.Sys_Test
- delete from 表名称 where 列名称 = 值 eg: delete from dbo.Sys_Test where test=’test’
drop,truncate,delete区别
1、drop (删除表):删除内容和定义,释放空间。简单来说就是把整个表去掉.以后要新增数据是不可能的,除非新增一个表。
drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
2、truncate (清空表中的数据):删除内容、释放空间但不删除定义(保留表的数据结构)。与drop不同的是,只是清空表数据而已。
注意:truncate 不能删除行数据,要删就要把表清空。
3、delete (删除表中的数据):delete 语句用于删除表中的行。delete语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存
以便进行进行回滚操作。
truncate与不带where的delete :只删除数据,而不删除表的结构(定义)
4、truncate table 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用delete。
如果要删除表定义及其数据,请使用 drop table 语句。
5、对于由foreign key约束引用的表,不能使用truncate table ,而应使用不带where子句的delete语句。由于truncate table 记录在日志中,所以它不能激活触发器。
6、执行速度,一般来说: drop> truncate > delete。
7、delete语句是数据库操作语言(dml),这个操作会放到 rollback segement 中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。
truncate、drop 是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
连表查询
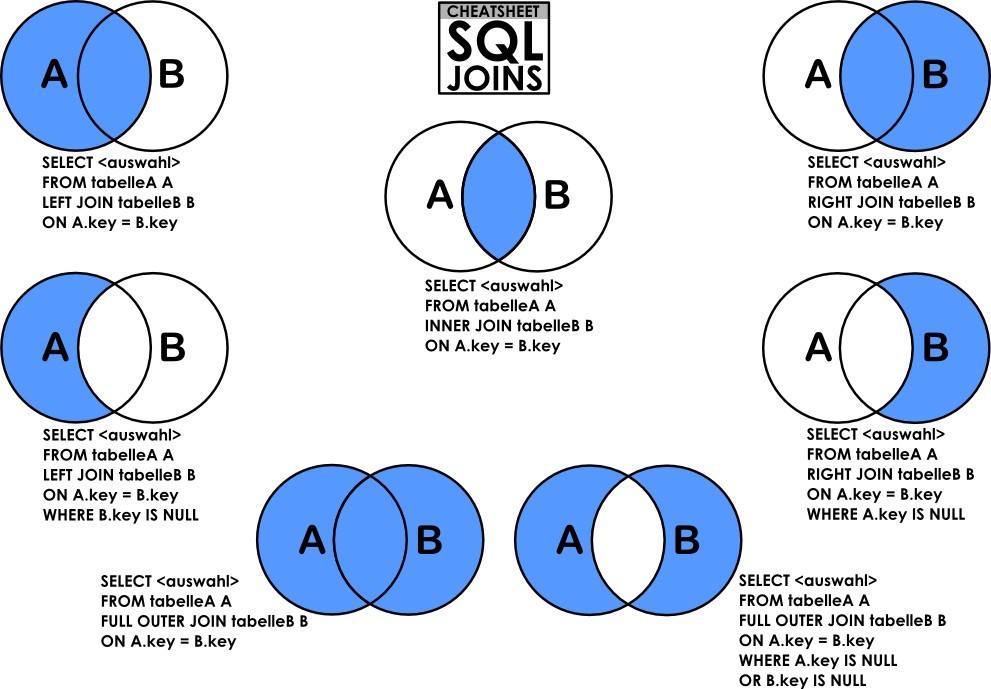
Mysql的join算法
1 | CREATE TABLE `t2` ( |
Simple Nested-Loop
简单嵌套循环连接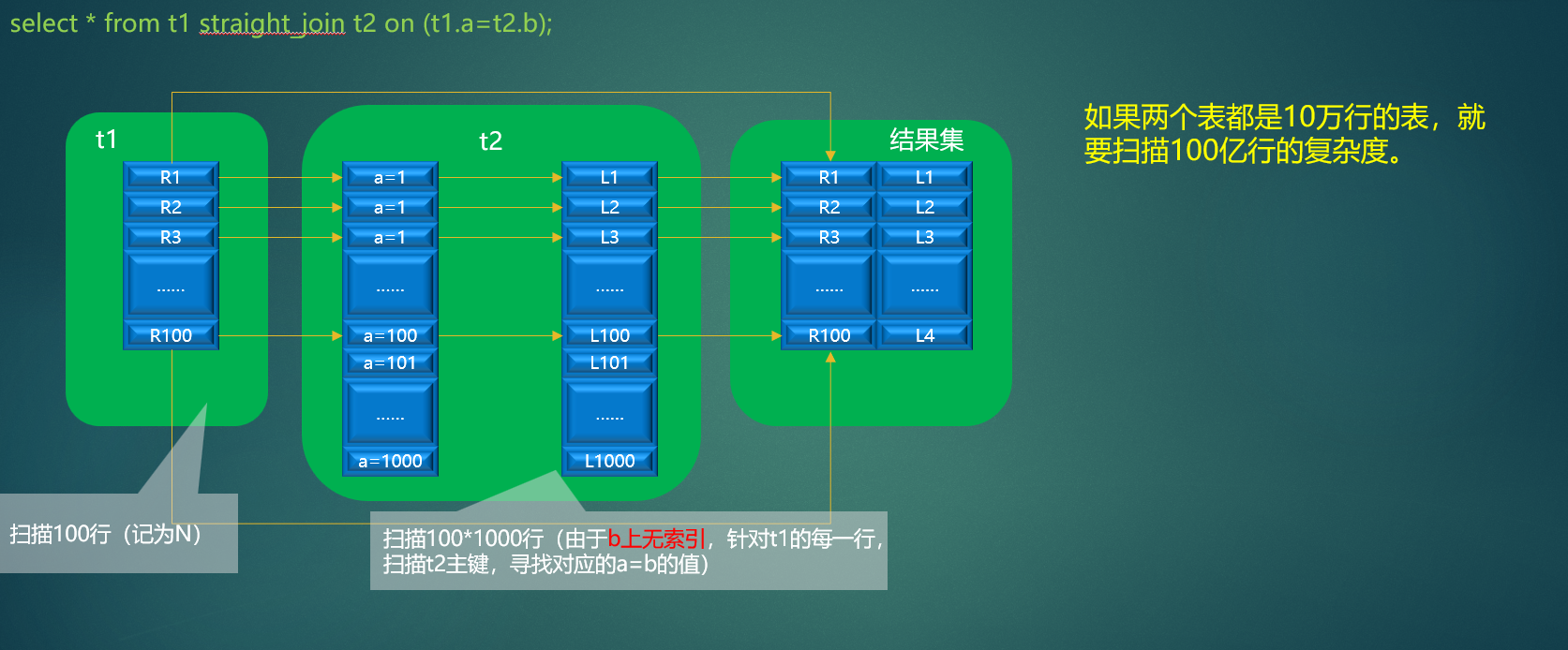
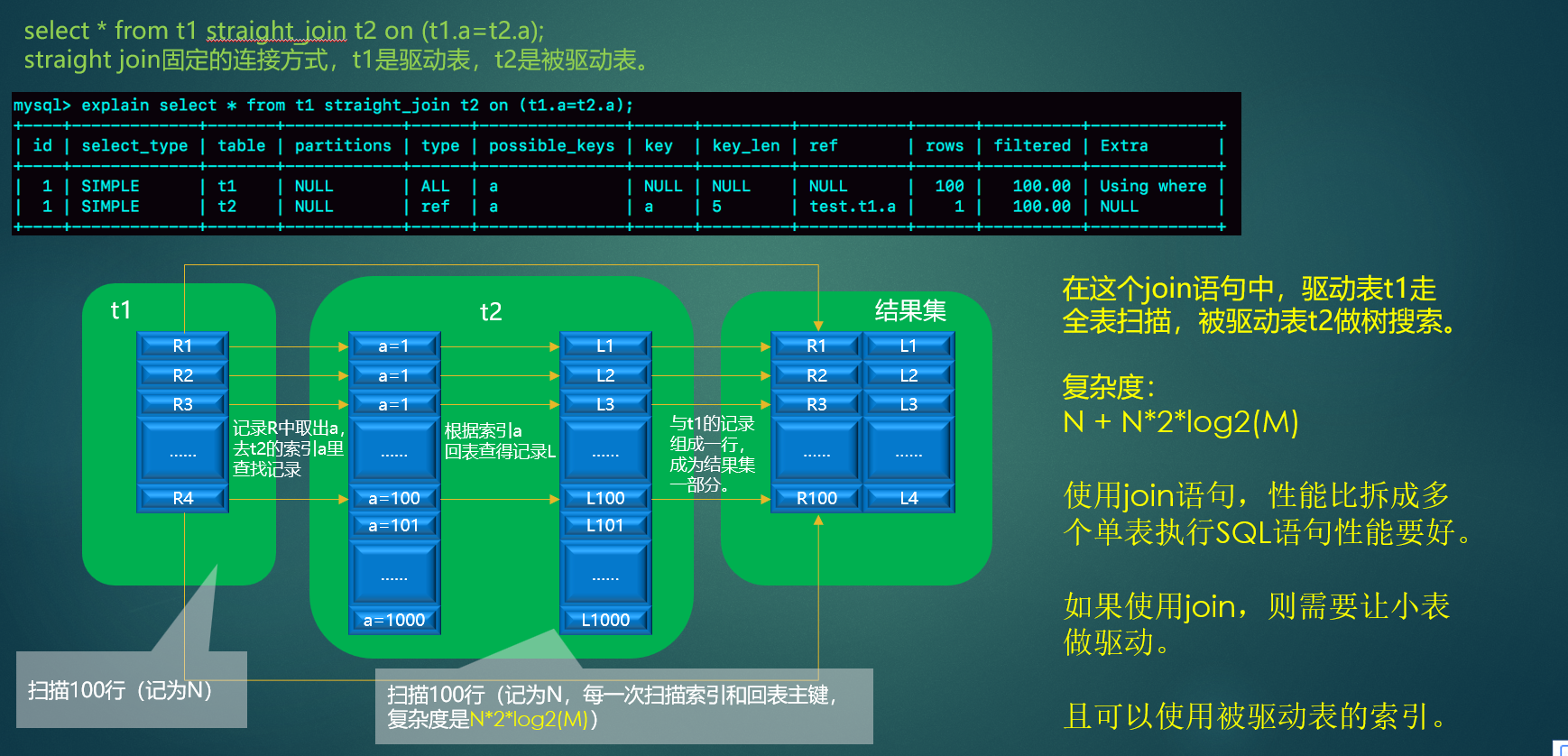
Index Nested-Loop Join
索引嵌套循环连接,只有内层表join的列有索引时,才能用到Index Nested-LoopJoin进行连接
原来的匹配次数 = 外层表行数 * 内层表行数
优化后的匹配次数= 外层表的行数 * 内层表索引的高度
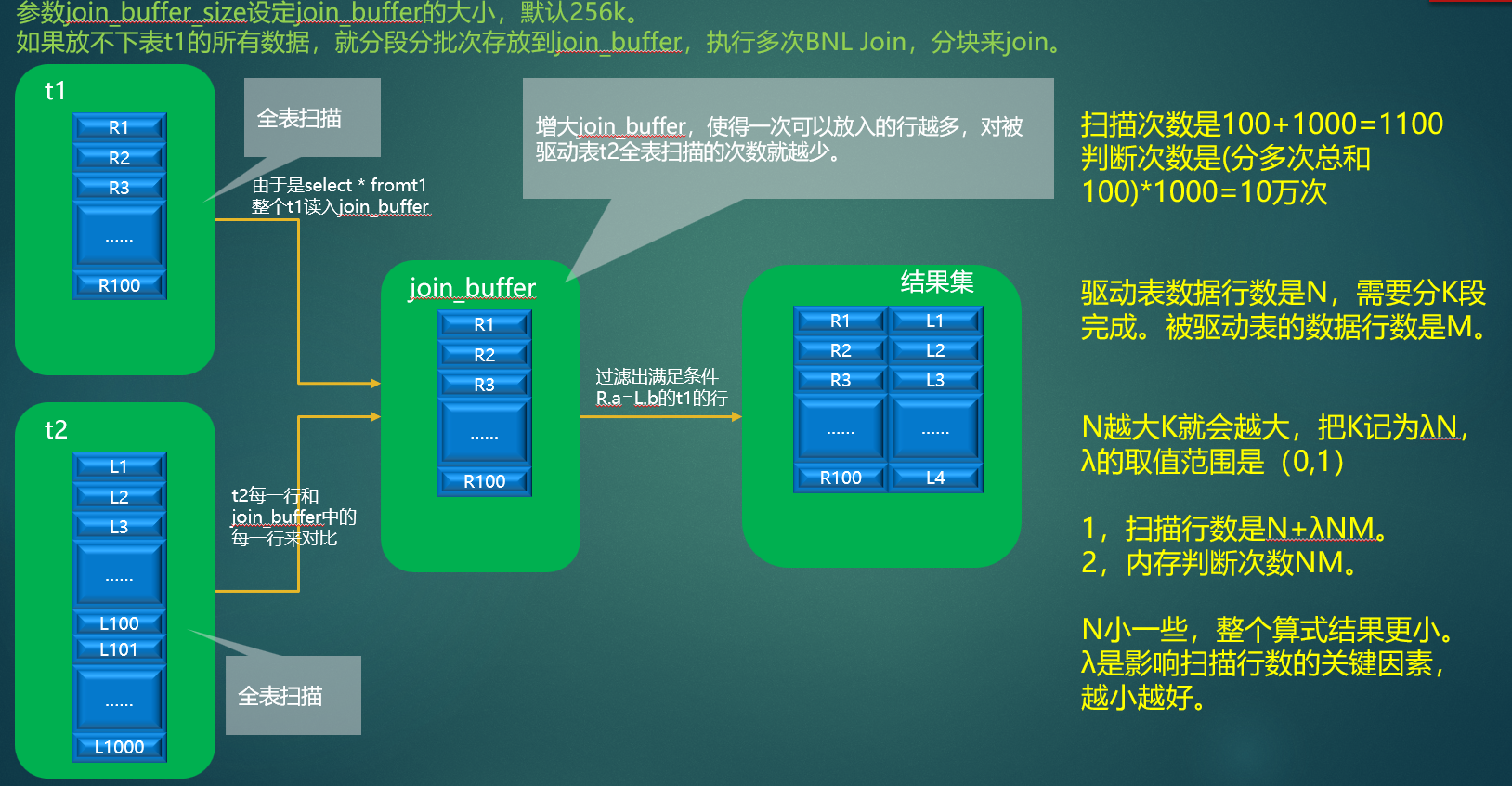
Block Nested-Loop Join
缓存块嵌套循环连接
什么是Join Buffer?
块嵌套循环(BNL)联接算法将外循环中读取行放在缓冲区来减少内循环中表必须被读取的次数。例如,如果将10条记录读入缓冲区,并将缓冲区传递给下一个内循环,那么内循环中读取的每条记录都可以与缓冲区中的所有10条记录进行比较。这就使内层循环的表必须被读取的次数减少了一个数量级。
在MySQL 8.0.18之前,这种算法适用于不能使用索引的等价联接(equi-joins);在MySQL 8.0.18及以后的版本中,这种情况会采用哈希联接优化。从MySQL 8.0.20开始,MySQL不再使用块嵌套循环,在以前使用块嵌套循环的所有情况下都采用哈希联接(Hash Join)。
MySQL join buffer具有以下特征:
- 当联接的类型为ALL或index或range时可以使用join buffer。
- 永远不会给第一个非Constant Table分配join buffer,即使它的类型是ALL或index。
- 只有参与join的列存储在join buffer中,而不是整个行。
- 系统变量join_buffer_size决定了用于处理查询的每个缓冲区的大小。–调优
- 为每个可以缓冲的联接分配一个缓冲区,因此一个查询可以使用多个缓冲区来处理。
- 在执行联接(join)之前分配(allocate)缓冲区,并在查询完成后释放(free)缓冲区。
哈希联接(Hash Join)
通常将Hash Join分为两个阶段。构建阶段(build phase)和探测阶段(probe phase)。
在构建阶段,从其中一个表输入(通常是两个中较小的一个)构建内存中的哈希表,服务器使用联接属性作为哈希表键。一旦所有行都存储在哈希表中,就完成了构建阶段。
在探测阶段,将第二个表的每一行计算联接键哈希,并检查它是否存在于在构建阶段创建的哈希表中。如果找到该哈希的匹配项,则它还需验证哈希表中的行与第二个表中的行之间的联接键是否真的匹配(由于存在哈希冲突)
常用的sql语句
sql比较两张表数据是否一致
1 | select * |
