MySQL数据库:用户相关操作
安装mysql
https://www.runoob.com/../images/mysql/mysql-install.html
mysql的存储引擎
查看引擎语句
show engines; 查看所有的引擎
SHOW VARIABLES LIKE 'default_storage_engine'; 查看当前默认引擎
1 | 存储引擎 -- 存储数据的方式 |
数据库的基本操作
用户相关操作
1 | 查看当前用户是谁? select user(); |
数据库相关的操作
1 | 创建库 create database 数据库名; |
表相关的操作
1 | 查看这个库下的所有表 show tables; |
数据类型
数字类型
这5种整型的占用空间是固定的,均与其后设置的 n 无关(它的含义是“显示位宽”,这个 n 无论填任何数,不影响存储环节,仅影响在检索时的输出格式,而且在非常严格的情况下才成立。),例如设置字段类型为 int ,则无论 n 设置什么,它占用的空间就是4个字节。
这5种整型的占用空间分别是:
1 | tinyint :1个字节, |
**注意:**当插入的值,超出取值范围的时候,MySQL并不会报错,而是自动变成成在取值范围内最接近该值的边界值。例如字段为 tinyint ,有符号型时取值范围 -128至127 ,当你输入-222时,不会报错,会自动存入最接近-222的-128,当你输入222时,会自动存入127。
创建表
1 | create table t1 ( |
浮点类型
FLOAT 类型固定占用4个字节, DOUBLE 类型固定占用8个字节。
它的定义方式是 DECIMAL(M,D) ,其中 M 表示最大位数,D 表示小数点右侧的位数。这里的“位”不是二进制的比特位,而是指十进制的数字的位数。
例如:
我们定义 DECIMAL(5,2) ,则表示最大位数为5位,小数点后2位,因此小数点前还剩下3位,于是取值范围为 -999.99至999.99。位数多了四舍五入。
DECIMAL:
对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
CHAR(n) 和 VARCHAR(n) 两者中的 n 含义均为该字段最大可容纳的字符数
CHAR(4) 表示固定容纳4个字符,当少于4个字符时,会使用空格填充空缺的部分,使其达到4个字符。而VARCHAR(4) 类型对于未达到 n 字符的情况不会补空
注意:varchar(n) 字段类型的 n 代表的是最多存储的字符数量,并不是字节大小。
varchar 是变长的,变长字段实际存储的数据的长度(大小)不固定的。
所以,在存储数据的时候,也要把数据占用的大小存起来,存到「变长字段长度列表」里面,读取数据的时候才能根据这个「变长字段长度列表」去读取对应长度的数据。
要算 varchar(n) 最大能允许存储的字节数,还要看数据库表的字符集,因为字符集代表着,1个字符要占用多少字节,比如 ascii 字符集, 1 个字符占用 1 字节,那么 varchar(100) 意味着最大能允许存储 100 字节的数据。
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个”零”值,当指定不合法的MySQL不能表示的值时使用”零”值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
ENUM和SET类型
ENUM:单选,在规定的范围内选择一个
SET:多选,在规定的范围内选择多个
约束
MYSQL中,常用的几种约束:
| 约束类型: | 主键 | 外键 | 唯一 | 非空 | 自增 | 默认值 |
|---|---|---|---|---|---|---|
| 关键字: | primary key | foreign key | unique | not null | auto_increment | default |
主键
第一个被定义为非空+唯一的列会自动成为主键。
- 每个表只能定义一个主键。
- 主键值必须唯一标识表中的每一行,且不能为 NULL,即表中不可能存在两行数据有相同的主键值。这是唯一性原则。
- 一个列名只能在复合主键列表中出现一次。
- 复合主键不能包含不必要的多余列。当把复合主键的某一列删除后,如果剩下的列构成的主键仍然满足唯一性原则,那么这个复合主键是不正确的。这是最小化原则。
唯一
字段唯一不重复
联合唯一
自增
只对数字有效,自带非空约束
至少是unique的约束之后才能使用auto_increment
外键
外键删除:
CASCADE:父表delete、update的时候,子表会delete、update掉关联记录;
SET NULL:父表delete、update的时候,子表会将关联记录的外键字段所在列设为null,所以注意在设计子表时外键不能设为not null;
RESTRICT:如果想要删除父表的记录时,而在子表中有关联该父表的记录,则不允许删除父表中的记录;
NO ACTION:同 RESTRICT,也是首先先检查外键;
单表查询
Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
1 | 1.select语句 |
连表查询
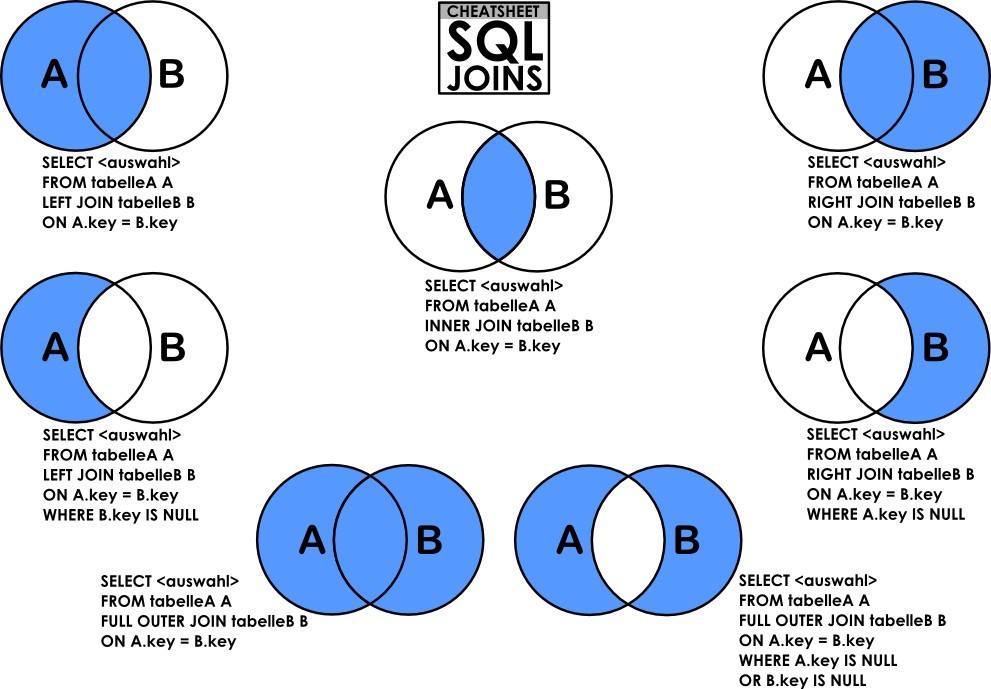
索引
一、索引定义
索引(Index)是帮助Mysql高效获取数据等数据结构。
索引是排好序的快速查找数据结构,故影响sql执行中的查找和排序。
二、索引的优势和劣势
2.1 索引优势
索引大幅度提高了查询效率,降低了数据库的IO成本。降低了数据排序成本,降低了CPU的消耗。
2.2 索引劣势
因为索引是一个独立的表,里面存了主键与索引字段,并且指向实体表的记录,所以也是占空间的。并且虽然有了所以之后查询速度快,但是对相应数据更新(insert、update、delete)的速度变慢了,所以对于那些经常需要更新的数据表尽量不要加索引。
三、索引分类
我们可以按照四个角度来分类索引。
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
3.1 主键索引
主键索引就是建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。
在创建表时,创建主键索引的方式如下:
1 | CREATE TABLE table_name ( |
3.2 唯一索引
唯一索引建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。
在创建表时,创建唯一索引的方式如下:
1 | CREATE TABLE table_name ( |
建表后,如果要创建唯一索引,可以使用这面这条命令:
1 | CREATE UNIQUE INDEX index_name |
3.3 普通索引
普通索引就是建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。
在创建表时,创建普通索引的方式如下:
1 | CREATE TABLE table_name ( |
建表后,如果要创建普通索引,可以使用这面这条命令:
1 | CREATE INDEX index_name |
3.4 前缀索引
前缀索引是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。
使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
在创建表时,创建前缀索引的方式如下:
1 | CREATE TABLE table_name( |
建表后,如果要创建前缀索引,可以使用这面这条命令:
1 | CREATE INDEX index_name |
3.5 联合索引
通过将多个字段组合成一个索引,该索引就被称为联合索引。
CREATE INDEX index_name ON TABLE(A, B);
3.6 聚簇索引
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
聚集索引(Innodb):
1、建表的时候,如果指定了主键,则主键就是聚簇索引。
2、建表的时候,如果没有指定主键,且含有唯一索引,则会选择一个唯一的非空索引作为聚簇索引。
3、如果即不含有主键,也不含有唯一索引,则隐式使用6个字节的rowId作为聚簇索引。
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
InnoDB普通索引的叶子节点存储主键值。
聚簇索引查找过程
如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据。 如:select * from user where age = 30;
1 | 1. 先通过普通索引 age=30 定位到主键值 id=1 |
回表查询
先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据,需要扫描两次索引B+树,它的性能较扫一遍索引树更低。
索引覆盖
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
例如:select id,age from user where age = 10;
如何实现覆盖索引
常见的方法是:将被查询的字段,建立到联合索引里去。
1、如实现:select id,age from user where age = 10;
explain分析:因为age是普通索引,使用到了age索引,通过一次扫描B+树即可查询到相应的结果,这样就实现了覆盖索引
四、索引的基本操作
- 查看索引
show index from tblname;
- 直接创建索引
CREATE INDEX index_name ON table(column(length))
- 修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
- 创建表的时候同时创建索引
1 | CREATE TABLE `table` ( |
- 删除索引
DROP INDEX index_name ON table
验证索引–explain
对于执行计划,参数有:
- possible_keys 字段表示可能用到的索引;
- key 字段表示实际用的索引,如果这一项为 NULL,说明没有使用索引;
- key_len 表示索引的长度;
- rows 表示扫描的数据行数。
- type 表示数据扫描类型,我们需要重点看这个。
- extra 几个重要的参考指标:
- Using filesort :当查询语句中包 含 group by 操作,而且无法利用索引 完成排序操作的时候, 这时不得不选择 相应的排序算法进行,甚至可能会通过文 件排序,效率是很低的,所以要避免这种 问题的出现。
- Using temporary:使了用临时表保 存中间结果,MySQL 在对查询结果排序 时使用临时表,常见于排序 order by 和分组查询 group by。效率低,要避免 这种问题的出现。
- Using index:所需数据只需在索引 即可全部获得,不须要再到表中取数据, 也就是使用了覆盖索引,避免了回表操 作,效率不错。
type 字段就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为:
- All(全表扫描)
- index(全索引扫描)
- range(索引范围扫描)
- range 表示采用了索引范围扫描,一般在 where 子句中使用 < 、>、in、between 等关键词,只检索给定范围的行,属于范围查找。从这一级别开始,索引的作用会越来越明显,因此我们需要尽量让 SQL 查询可以使用到 range 这一级别及以上的 type 访问方式。
- ref(非唯一索引扫描)
- ref 类型表示采用了非唯一索引,或者是唯一索引的非唯一性前缀,返回数据返回可能是多条。因为虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。
- eq_ref(唯一索引扫描)
- eq_ref 类型是使用主键或唯一索引时产生的访问方式,通常使用在多表联查中。比如,对两张表进行联查,关联条件是两张表的 user_id 相等,且 user_id 是唯一索引,那么使用 EXPLAIN 进行执行计划查看的时候,type 就会显示 eq_ref。
- const(结果只有一条的主键或唯一索引扫描)。
- const 类型表示使用了主键或者唯一索引与常量值进行比较,比如 select name from product where id=1。
- 需要说明的是 const 类型和 eq_ref 都使用了主键或唯一索引,不过这两个类型有所区别,const 是与常量进行比较,查询效率会更快,而 eq_ref 通常用于多表联查中。
五、创建索引建议
5.1 适合建索引
a、主键自动建立唯一索引
b、频繁作为查询条件的字段时候建立索引
c、查询中与其它表关联的字段,外键关系建立索引
d、where 里用不到的不建立索引
e、查询中排序的字段,建立索引将大大提高排序速度
f、查询中统计或分组的字段
5.2 不适合建索引
- WHERE 条件,GROUP BY,ORDER BY 里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。
- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女,如果数据库表中,男女的记录分布均匀,那么无论搜索哪个值都可能得到一半的数据。在这些情况下,还不如不要索引,因为 MySQL 还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
5.3 索引失效
- 当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx%这两种方式都会造成索引失效;
- 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
六、Mysql索引结构
MySql索引使用的数据结构是B+树
- 不使用Hash存储的原因是
a、使用hash存储必须使用好的hash算法。
b、hash存储由于数据分布的不均衡,比较占用内存。
c、hash存储不能进行范围查询,范围查询多于等值查询。(关键点)
- 不使用二叉树、BST、AVL、红黑树的原因:
当插入的节点越来越多,会导致树的深度越来越深,导致查询变慢。
七、关于索引的常见问题
- B+树有多少层
3~4层足够
- 索引用int 还是varchar
索引字段存储空间越小越好
- 索引为什么要自增
会引起底层的数据分裂或合并,影响性能
数据库使用的时候有什么注意事项
1 | 从搭建数据库的角度上来描述问题 |
最左前缀原则
什么是最左前缀原则?什么是最左匹配原则
顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
事物
- 原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
