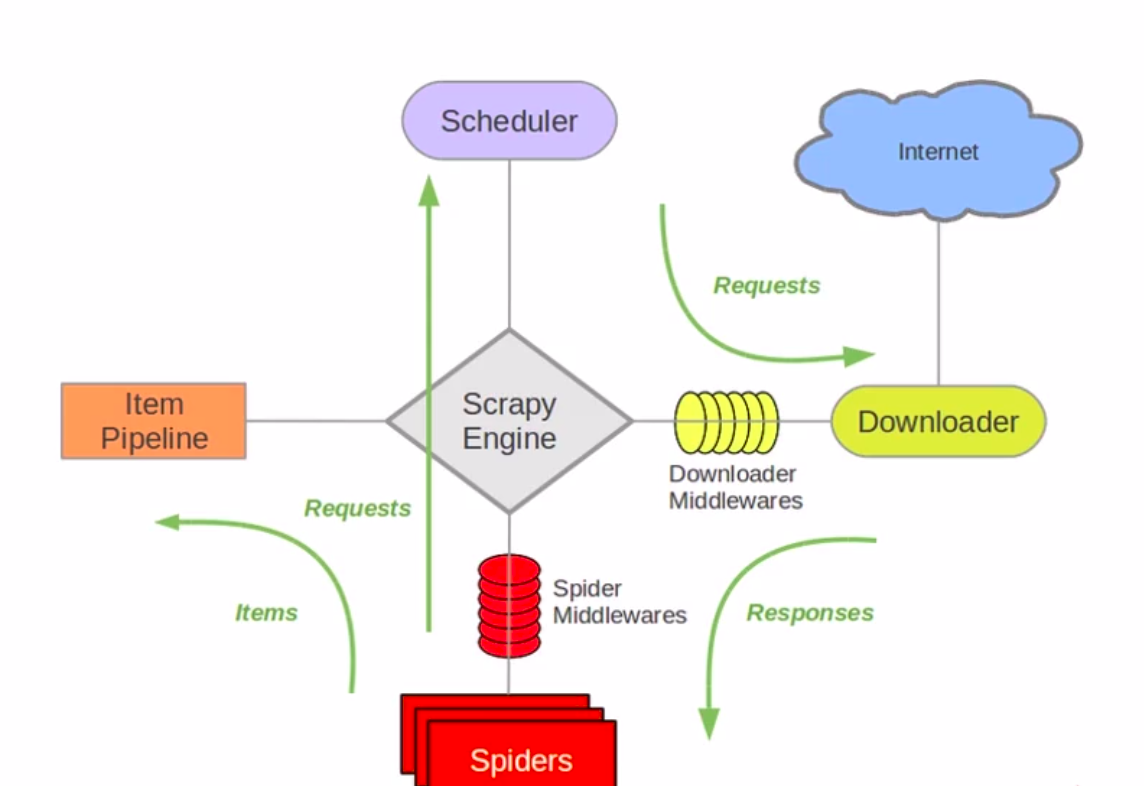
Scrapy基础:[Scrapy](https://doc.scr…
Scrapy
新建一个项目的命令:
1 | scrapy startproject 项目的名称 |
新建一个爬虫项目:
1 | Available templates: |
运行爬虫:
\Lib\site-packages\scrapy
1 | scrapy crawl 爬虫的项目名称 |
scrapy重点命令学习:
scrapy命令分俩类:
1.全局命令:
*startproject 建立一个项目(不是爬虫项目)
settings 获取配置文件 #scrapy settings –get BOT_NAME
*runspider 运行spider # scrapy runspider <spider_file.py>
*shell 打开scrapyshell,做测试
fetch 将网页内容下载下来,然后在终端打印当前返回的内容
view 将网页内容保存下来,并在浏览器中打开当前网页内容,直观呈现要爬取网页的内容
version 查看scrapy以及所依赖包的版本2.爬虫项目里面的命令:
*crawl 开始爬虫
check 检测项目有没有问题
list 列出当前项目的目录
edit 编辑爬虫
parse 获取给定的URL并使用相应的spider分析处理
*genspider 创建爬虫的项目
*deploy 打包上传服务器 # scrapy deploy [ target:project | -l| -L ]
bench 测试电脑当前爬取速度性能scrapy shell具体学习
scrapy 爬虫数据文件导出:
scrapy 内置主要有四种:JSON,JSON lines,CSV,XML
我们将结果用最常用的JSON导出,命令如下:
1
scrapy crawl dmoz -o douban.json -t json -s FEED_EXPORT_ENCODING=UTF-8
scrapy shell 目标网址:
- 主要用于调式代码,十分重要
scrapy配置信息
setting配置:
* 默认: 'scrapybot',当您使用 startproject 命令创建项目时其也被自动赋值。
BOT_NAME = 'mySpider'
爬虫应用路径
SPIDER_MODULES = ['mySpider.spiders']
NEWSPIDER_MODULE = 'mySpider.spiders'
客户端 user-agent请求头
USER_AGENT = 'mySpider (+http://www.yourdomain.com)'
禁止爬虫配置
ROBOTSTXT_OBEY = False
并发请求数
CONCURRENT_REQUESTS = 32
延迟下载秒数
DOWNLOAD_DELAY = 3
单域名访问并发数,并且延迟下次秒数也应用在每个域名
CONCURRENT_REQUESTS_PER_DOMAIN = 16
单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP
CONCURRENT_REQUESTS_PER_IP = 16
是否支持cookie,cookiejar进行操作cookie
COOKIES_ENABLED = True
COOKIES_DEBUG = True
Telnet用于查看当前爬虫的信息,操作爬虫等...
使用telnet ip port ,然后通过命令操作
TELNETCONSOLE_ENABLED = True
TELNETCONSOLE_HOST = '127.0.0.1'
TELNETCONSOLE_PORT = [6023,]
默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
爬虫中间件
SPIDER_MIDDLEWARES = {
'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
}
下载中间件
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
}
自定义扩展,基于信号进行调用
EXTENSIONS = {
'scrapy.extensions.telnet.TelnetConsole': None,
}
定义pipeline处理请求
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
}
爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
DEPTH_LIMIT = 3
爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo
后进先出,深度优先
DEPTH_PRIORITY = 0
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
先进先出,广度优先
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
调度器队列
SCHEDULER = 'scrapy.core.scheduler.Scheduler'
from scrapy.core.scheduler import Scheduler
访问URL去重
DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl'
开始自动限速
AUTOTHROTTLE_ENABLED = True
初始下载延迟
AUTOTHROTTLE_START_DELAY = 5
最大下载延迟
AUTOTHROTTLE_MAX_DELAY = 60
平均每秒并发数
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
是否显示
AUTOTHROTTLE_DEBUG = False
是否启用缓存策略
HTTPCACHE_ENABLED = True
缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy"
缓存超时时间
HTTPCACHE_EXPIRATION_SECS = 0
缓存保存路径
HTTPCACHE_DIR = 'httpcache'
缓存忽略的Http状态码
HTTPCACHE_IGNORE_HTTP_CODES = []
缓存存储的插件
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
scrapy中间件学习(分值越小,优先级越高):
scrapy中有俩个中间件,一个是下载中间件(DownloaderMiddleware),一个是蜘蛛中间件(SpiderMiddleware)
DownloaderMiddleware:
当调度器拿出一个request发送给downloader下载的时候,会经过下载中间件,然后当downloader下载完之后,返回response给spider的时候也会再次经过下载中间件
下载中间件是处于引擎和下载器之间,可以用来修改Request和Response
def process_request(self, request, spider)
process_request()必须需返回一下其中之一:
None:如果返回None:Scrapy将继续处理request,执行其他的中间件的响应方法
Response 对象:
如果返回 Response 对象: Scrapy不会再调用任 何其他的中间件的 process_request() 或相应地下 载函数; 直接返回这个response对象。 已激活的中间件的 **process_response()**方法则会在 每个 response 返回时被调用。
Request 对象:
如果返回 Request 对象,Scrapy则停止调用 其他中间件的process_request方法,并重新将返回的 request对象放置到调度器等待下载。
IgnoreRequest异常
如果返回raise IgnoreRequest 异常: 下载中间件的 process_exception() 方法会被用。 如果没有捕获该异常, 则request发情请求时设置的 errback(Request.errback)方法会被调用。如果也 没有设置异常回调,则该异常被忽略且不记录
主要作用:
1.随机请求头
2.代理中间件
3.cookie登录
4.网页动态加载
…
SpiderMiddleware:
当downloader下载完成之后,返回给spider的时候,发送之前会经过蜘蛛中间件,然后当spider处理生成item和request之后,还会经过蜘蛛中间件一次。
详细参考:https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/spider-middleware.html
scrapy-redis
scrapy_redis分布式配置
如果不配下列文件,scrapy的调度引擎默认走的是
1 | D:\python3.7.5\Lib\site-packages\scrapy\下的文件 |
而不是scrapy_redis。
一般在配置文件中添加如下几个常用配置选项:
1(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
1 | DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" |
2(必须). 使用了scrapy_redis的调度器,在redis里分配请求
1 | SCHEDULER = "scrapy_redis.scheduler.Scheduler" |
3(可选). 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
1 | SCHEDULER_PERSIST = True |
4(可以自定义). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item 这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
1 | ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 100 ,} |
5(必须). 指定redis数据库的连接参数
1 | REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 |